This is the introductory page. Here you can find some basic information about the API.
For API documentation, visit /docs.
# Import necessary libraries
import pandas as pd
import json
import requests
# Define the file path and read the CSV file
filepath = r"example\L111A_fm.csv"
df = pd.read_csv(filepath)
dataframe = df.to_dict(orient="records")
#or get the example dataframe from the API
r=requests.get("https://nogeo-geotolkapi.azurewebsites.net/example_dataframe_fm")
df=pd.read_json(r.json())
# Convert timestamp columns to string format
df['created_at'] = df['created_at'].astype(str)
df['updated_at'] = df['updated_at'].astype(str)
dataframe = df.to_dict(orient="records")
# Define the parameters for the API request
params = {
"max_layers": 2,
"min_depth_layer": 0.5,
"classify_bedrock": True,
"plot_proba": True,
"smoothing_depth_layers": 1,
"convertLayersStandard": True,
"from_geotolk": True,
"writeWhere": "Somewhere",
}
# Define the metadata for the API request
metadata = {"x": 0.0, "y": 0.0, "z": 0.0}
# Prepare the payload for the API request
payload = {
"params": params,
"dataframe": {
"data": dataframe,
},
"metadata": metadata,
}
payload = json.dumps(payload)
# Define the API URL and headers
API_URL = "https://nogeo-geotolkapi.azurewebsites.net"
headers = {
"Content-Type": "application/json",
}
# Send the POST request to pred the FM dataframe
response = requests.post(
API_URL + "/pred/fm_dataframe", data=payload, headers=headers
)
#If original csv/dataframe is on the format of FGD, use the following endpoint
response = requests.post(
API_URL + "/pred/fgdb_dataframe", data=payload, headers=headers
)
# Process the response
if response.status_code == 200:
response_data = response.json()
tlk = pd.DataFrame(response_data["TLK"])
display(tlk)
else:
print("Error:", response.status_code)
print(response.text)
The response from the API is structured as follows:
from pydantic import BaseModel, root_validator
from typing import List, Optional
class TLKItem(BaseModel):
start: float
stop: float
type: str
probability: float
manual_label: int
input_filename: str
kote: float
max_depth: float
x: float
y: float
class QUICKCLAYItem(BaseModel):
start: float
stop: float
type: str
probability: float
class STATIC_DATAItem(BaseModel):
Dybde: float
Udrenert: float
Drenert: float
Harde_masser: Optional[float] = None
Trykk: Optional[float] = None
Spyletrykk: Optional[float] = None
Oekt_rotasjon: Optional[float] = None
Spyling: Optional[float] = None
Bortid: Optional[float] = None
Slagboring: Optional[float] = None
@root_validator(pre=True)
def rename_keys(cls, values):
if "Harde masser" in values:
values["Harde_masser"] = values.pop("Harde masser")
return values
class SND_METADATA(BaseModel):
x: float
y: float
z: float
class ResponseGeotolk(BaseModel):
SND_METADATA: SND_METADATA
STATIC_DATA: List[STATIC_DATAItem]
TLK: List[TLKItem]
QUICK_CLAY_LAYERS: Optional[List[QUICKCLAYItem]] = []
This response model includes several components:
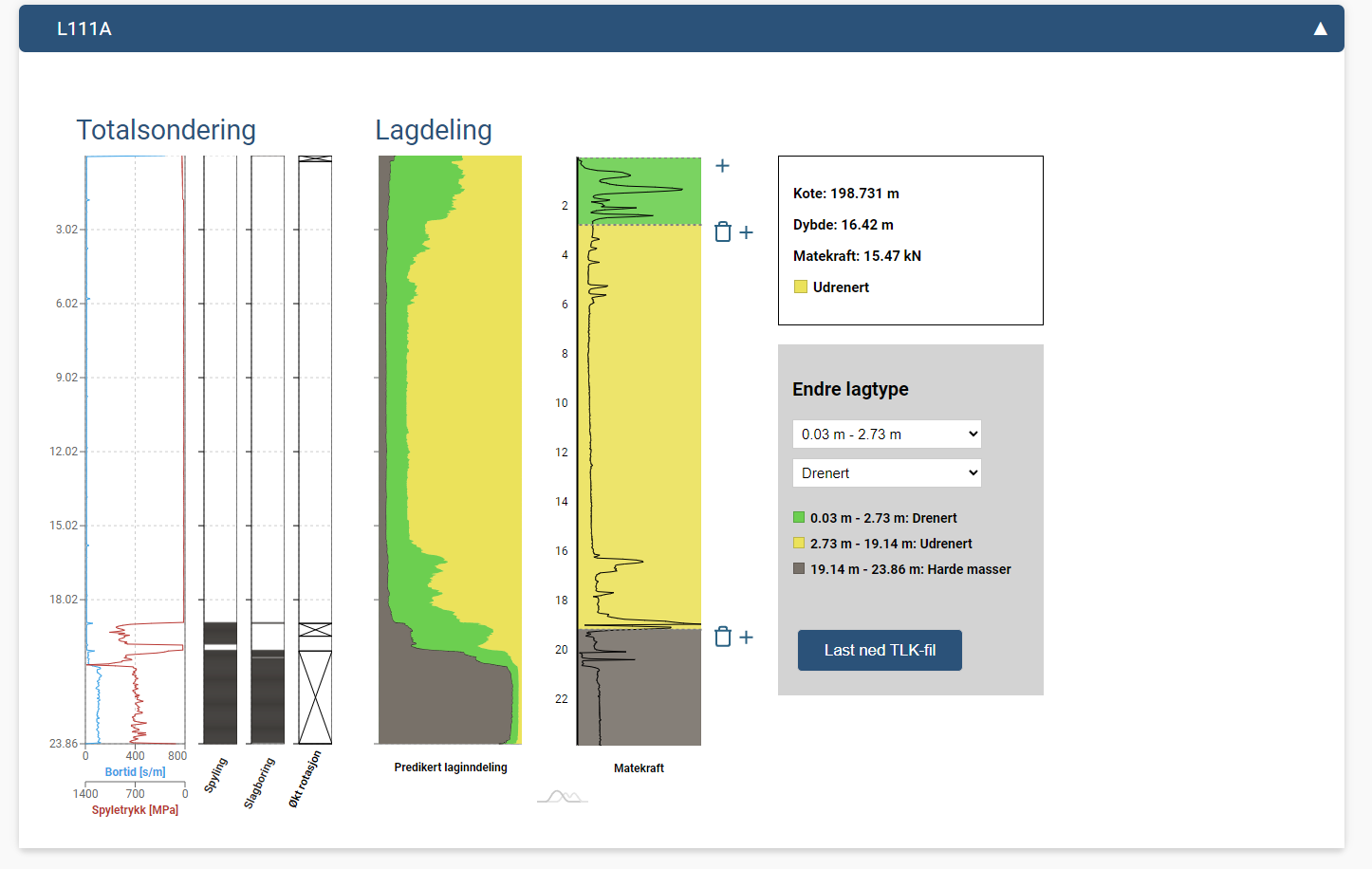
SND_METADATA: Metadata including coordinates.STATIC_DATA: A list of static data items containing the probability of each layer along the depth, its shown on the "Lagdeling" plot on the picture belowTLK: A list the layers that geotolk predicts given the input parameters. Based on the input parameters, like min_depth_layer and smoothing_depth_layers, the layers will change, since its the sum of the largest proability .QUICK_CLAY_LAYERS: An optional list of quick clay items from probability, this is a beta test for finding possible quickclay layers in a sounding.Here is an image that visually represents the response structure: